

 Hugging Face - это компания, которая специализируется на разработке искусственного интеллекта (AI) и машинного обучения. Они разрабатывают инструменты и библиотеки, упрощающие работу с AI, включая библиотеку Transformers, которая является одной из самых востребованных и мощных библиотек для работы с моделями глубокого обучения. В этой статье мы рассмотрим технологии, созданные компанией Hugging Face и их влияние на сферу искусственного интеллекта и машинного обучения.
Hugging Face - это компания, которая специализируется на разработке искусственного интеллекта (AI) и машинного обучения. Они разрабатывают инструменты и библиотеки, упрощающие работу с AI, включая библиотеку Transformers, которая является одной из самых востребованных и мощных библиотек для работы с моделями глубокого обучения. В этой статье мы рассмотрим технологии, созданные компанией Hugging Face и их влияние на сферу искусственного интеллекта и машинного обучения.
Что такое Hugging Face
Компания была основана в 2016 году Клементом Деланноем (Clement Delangue) и Томом Вулфом (Thomas Wolf) в Нью-Йорке. Их главная цель – сделать передовые технологии ИИ в области обработки естественного языка доступными для всех. Hugging Face стала популярной благодаря своей библиотеке Transformer, которая быстро стала одной из самых популярных инструментов для NLP-разработчиков.
Однако Hugging Face не только предоставляет библиотеку Transformer, но и поддерживает исследования в области ИИ и NLP. Компания активно участвует в различных научных исследованиях, проводит конкурсы и соревнования по NLP. В 2020 году Hugging Face запустила маркетплейс моделей, где разработчики могут обмениваться и коммерчески распространять свои модели.
Hugging Face получила большую поддержку сообщества. Продукты компании исследуются и применяются в различных областях, включая машинный перевод, анализ тональности текста, генерация текста, распознавание речи и многое другое.
Начало работы с Hugging Face
Чтобы начать работать с Hugging Face необходимо перейти на сайт и зарегистрироваться. https://huggingface.co/
Далее заходим на сайт под своими логином и паролем и попадаем на главную страницу
Далее можно нажать на кнопку "Models" для выбора необходимой модели
 Кроме моделей в чистом виде (где не всегда есть API вывод, можно использовать готовые пространства.
Кроме моделей в чистом виде (где не всегда есть API вывод, можно использовать готовые пространства.
Пространство (Spaces) в Hugging Face - это платформа и сообщество, посвященные разработке и предоставлению инструментов для работы с моделями и данных в области обработки естественного языка (Natural Language Processing, NLP). Hugging Face предоставляет библиотеки, датасеты и модели, а также инструменты для их совместного использования и обмена, чтобы улучшить текущие методы исследования в области NLP.
В пространстве Hugging Face можно найти заранее обученные модели для разных задач NLP, таких как классификация текста, распознавание сущностей, генерация текста и многое другое. Эти модели можно использовать с помощью библиотеки Transformers, которая предоставляет удобный интерфейс для загрузки, использования и дообучения моделей.
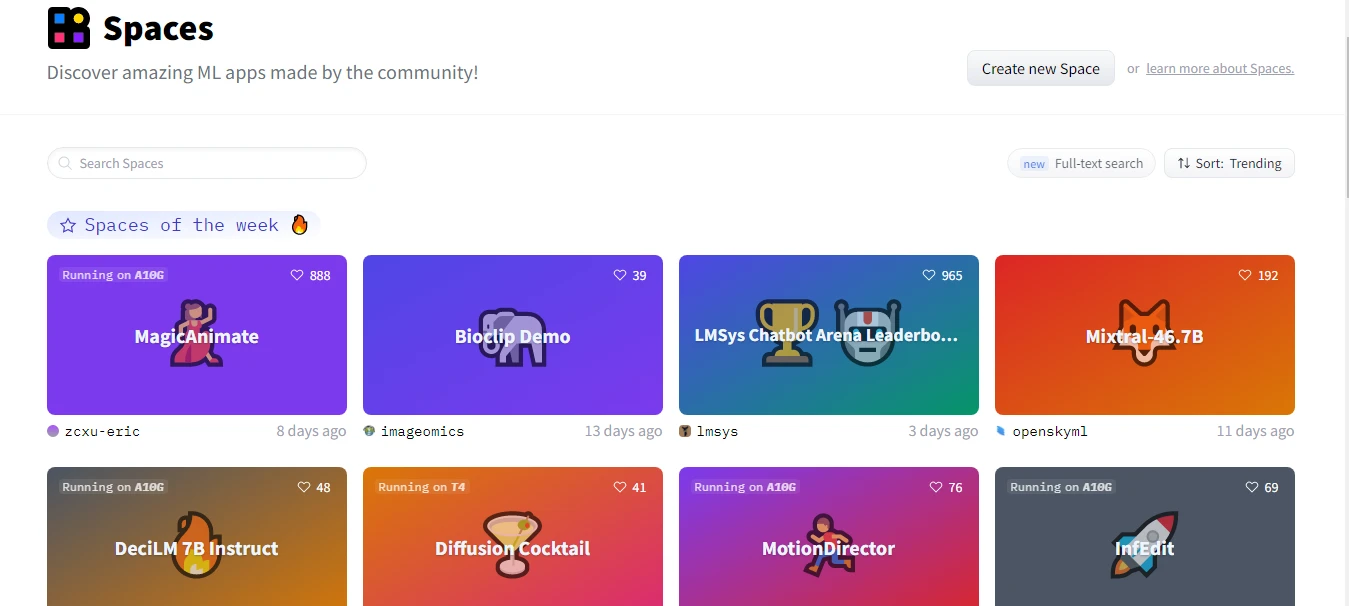
Hugging Face также хранит и предоставляет доступ к широкому спектру датасетов для NLP, которые могут быть использованы для обучения и оценки моделей. Эти датасеты могут быть загружены с помощью библиотеки Datasets, которая позволяет легко получать доступ к различным наборам данных и извлекать необходимую информацию из них.
Благодаря этому пространству и ресурсам Hugging Face исследователи и разработчики в области NLP могут использовать уже существующие модели и датасеты, а также вносить свой вклад, обмениваться своими моделями и осуществлять сотрудничество с сообществом для улучшения результатов в NLP.
Transformers, библиотека для работы с моделями глубокого обучения
Transformers – это библиотека, разработанная компанией Hugging Face, которая позволяет легко и эффективно работать с моделями глубокого обучения для обработки естественного языка (Natural Language Processing). Она предоставляет простой и удобный интерфейс для использования и настройки широкого спектра предобученных моделей.
Библиотека Transformers предоставляет API для нескольких платформ глубокого обучения, включая TensorFlow и PyTorch. Она включает в себя предобученные модели, такие как BERT, GPT, XLNet, и многие другие. Каждая модель может быть использована для решения различных задач, таких как классификация текста, генерация текста, и вопросно-ответные системы.
Пример загрузки и использование предобученной модели BERT для классификации текста на два класса (положительный и отрицательный)
from transformers import BertTokenizer, BertForSequenceClassification # Загрузка предобученной модели BERT model_name = 'bert-base-uncased' tokenizer = BertTokenizer.from_pretrained(model_name) model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # Токенизация и преобразование текстовых данных text_1 = "This movie is great!" text_2 = "This movie is terrible!" encoded_inputs = tokenizer([text_1, text_2], padding=True, truncation=True, return_tensors='pt') # Классификация текста outputs = model(**encoded_inputs) predictions = outputs.logits.argmax(dim=1) print(predictions) # tensor([1, 0])
А вот пример создание собственной модели для генерации текста с использованием предобученной модели GPT-2
from transformers import GPT2Tokenizer, GPT2LMHeadModel # Загрузка предобученной модели GPT-2 model_name = 'gpt2' tokenizer = GPT2Tokenizer.from_pretrained(model_name) model = GPT2LMHeadModel.from_pretrained(model_name) # Генерация текста input_text = "Once upon a time" input_ids = tokenizer.encode(input_text, return_tensors='pt') outputs = model.generate(input_ids, max_length=50) generated_text = tokenizer.decode(outputs[0]) print(generated_text) # "Once upon a time in a faraway land, there lived a prince..."
А вот пример использования инструментов Hugging Face Transformers для предобработки текста, включая токенизацию и преобразование текста в численные последовательности
from transformers import BertTokenizer
# Создание экземпляра токенизатора
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Токенизация текста
text = "Привет, как дела?"
tokens = tokenizer.tokenize(text)
print(tokens)
# Вывод: ['привет', ',', 'как', 'дела', '?']
# Преобразование токенов в численную последовательность
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)
# Вывод: [7592, 1010, 3716, 8469, 1029]
Библиотека также позволяет легко дообучать предобученные модели на своих данных, что позволяет получить более точные результаты для конкретной задачи.
Пример
Для дообучения предобученных моделей с помощью Hugging Face Transformers необходимо выполнить следующие шаги:
Загрузите предобученную модель и токенизатор с помощью AutoModel и AutoTokenizer соответственно.
Например, для модели BERT можно использовать следующий код:
from transformers import AutoModel, AutoTokenizer # Загрузка предобученной модели model_name = "bert-base-uncased" model = AutoModel.from_pretrained(model_name) # Загрузка токенизатора tokenizer = AutoTokenizer.from_pretrained(model_name)
Подготовьте свои данные для дообучения. Обычно это представляет собой список текстовых строк или пар текстов (в случае задач с парами). Например:
train_texts = ["Пример текста 1", "Пример текста 2", ...]
- Преобразуйте свои данные в формат, понятный для модели и токенизатора. Для этого используйте метод
tokenizer.encode_plus()для каждого текста или пары текстов. Например:
input_ids = [] attention_masks = []
for text in train_texts:
encoding = tokenizer.encode_plus(text, add_special_tokens=True, truncation=True, max_length=512, padding='max_length', return_tensors='pt')
input_ids.append(encoding['input_ids'])
attention_masks.append(encoding['attention_mask'])
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
Создайте DataLoader для подачи данных в модель. Например:
from torch.utils.data import TensorDataset, DataLoader dataset = TensorDataset(input_ids, attention_masks) dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
Дообучите модель с помощью полученных данных. Например, для задачи классификации:
from transformers import AdamW
# Определение гиперпараметров
epochs = 3
learning_rate = 2e-5
weight_decay = 0.01
optimizer = AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
for epoch in range(epochs):
total_loss = 0
for batch in dataloader:
optimizer.zero_grad()
# Перемещение данных на устройство (например, GPU)
batch = tuple(t.to(device) for t in batch)
input_ids, attention_mask = batch
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs.logits
# Вычисление loss
loss = # ваш код для вычисления loss
# Обратное распространение и обновление параметров
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
print(f'Epoch {epoch+1}/{epochs}, Loss: {avg_loss}')
После дообучения модель готова к использованию для вашей конкретной задачи. Вы можете сохранить ее с помощью метода
model.save_pretrained()
для последующего использования.
Одной из ключевых особенностей библиотеки Hugging Face Transformers является то, что она активно поддерживается сообществом и имеет богатую документацию, которая помогает пользователям быстро освоить ее возможности.
Ключевые возможности Hugging Face
Hugging Face предоставляет широкий выбор предтренированных моделей для различных задач NLP, включая распознавание именованных сущностей, классификацию текста, генерацию текста и многое другое. Модели можно загрузить и использовать с помощью нескольких строк кода.
Пример
import os
import io
import sys
from PIL import Image
import requests
string = 'Ваш промт'
API_URL = "https://api-inference.huggingface.co/models/SG161222/Realistic_Vision_V1.4"
headers = {"Login": "Bearer "ваш ключ от Hugging Face" "}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.content
image_bytes = query({
"inputs": string,
})
image = Image.open(io.BytesIO(image_bytes))
image.save("result.png")
Этот код вызывает модель SD генерации картинок.
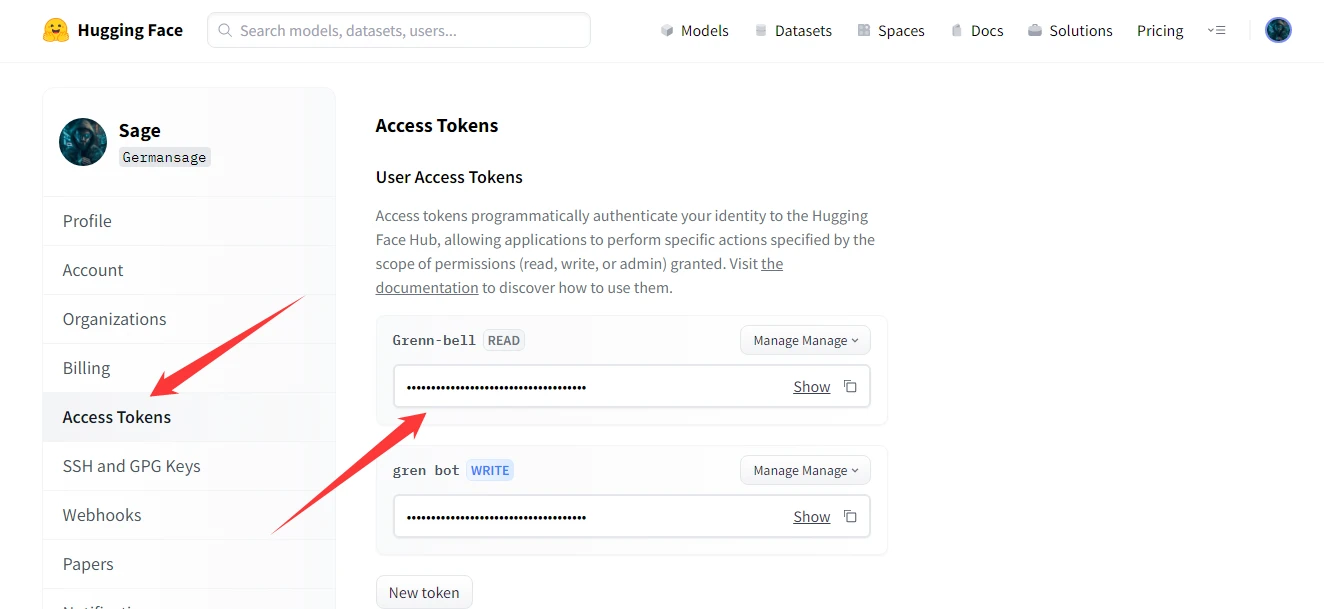
Для работы необходимо получить секретный токен. Он находится в личном кабинете.
Как видите все очень просто. Всего несколько строк кода. Но есть одно но. Так как модель находится в общем доступе то к ней могут обращатся тысячи пользователей одновременно, а это как вы понимаете заметно снижает возможности модели.
Кстати Hugging Face предоставляет возможность настройки и дообучения предтренированных моделей на пользовательских данных для оптимальной работы с конкретными задачами. Это позволяет достичь более высокой точности и улучшить результаты работы моделей. А так же поддерживать широкий набор архитектур моделей глубокого обучения, включая Transformer, BERT, GPT и многие другие. Библиотека обеспечивает удобный доступ к этим архитектурам и позволяет использовать их для решения различных задач NLP.
Hugging Face предоставляет простой и интуитивно понятный интерфейс для работы с моделями NLP. Большинство операций можно выполнить с помощью нескольких строчек кода, что значительно упрощает процесс разработки и экспериментирования с моделями.


